Check Which User Is Using Each Gpu on Linux Cluster
If you would like to test your GPU MPI program interactively you can do so on the GPGPU dialog nodes using our mpiexec wrapper MPIEXEC. This talk will focus on describing all building components for a cluster and complete software stack to run and manage it.

A Diagram Showing A Gpu Cluster Configuration Containing N Download Scientific Diagram
I have tried different options with qstat and qstatus but I cant seem to check by job name.
. If you are on a GPU front. The submission of a job only happens if such job is not already running. Sacct -a -X --formatJobIDAllocCPUSReqgres.
If you press the forward-slash you activate the less search function. Type VGA in all caps and press Enter. The goal is to build a research prototype GPU cluster using all open source and free software and with minimal hardware cost.
Glmark2 Then it will begin the test as follows and would stress test your GPU on Linux. Any command to check this would be of great use 2 Replies. My windows and Ubuntu system is the same.
GPU Cluster Configuration Notes Introduction. I am running a bash script to submit multiple jobs. Configuring Managed SLURM Cluster for Lightning.
Sudo apt install glmark2 Now run it as follows. Currently the cluster is working more like a group of workstations with remote access so some manual discovery is needed by the user such as available resources. Managed Clusters such as SLURM enable users to request resources and launch processes through a job scheduler.
I gave a talk on this topic at GTC 2013 session S3516 Building Your Own GPU Research Cluster Using Open Source Software Stack. Defining and Launching the EKS Cluster As discussed in previous sections there are three node-groups cpu-linux-client cpu-linux-lb and gpu-linux-workers. Hi I have an application running in four different nodeThe server is tomcatEach node in each tomcat serverHow do i check whether all the nodes are in cluster using shell script.
The Driver version P-State and BIOS version are displayed. LCs Linux commodity clusters can be divided into two types. There are three principal components used in a GPU cluster.
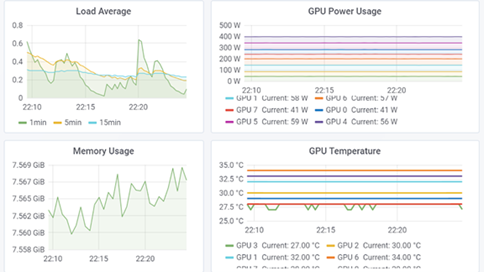
The GPU load RAM use Power Consumption and RAM frequency is displayed. The slides and a recording are available at that link so please check it out. The nVidia GPU shows as GeForce GTX970M with current GPU frequency and temperature.
Those having a high speed intra-node interconnect and those that dont. This document contains notes on configuring a cluster of machines with NVIDIA GPUs running Ubuntu Linux 1404 or later on a private network connected to a single master host that serves as the clusters network gateway file server and name service master. GPU Boost user-defined clocks Configure with nvidia-smi.
In a cluster stack this power combines with the computational resources of general CPUs of each of the multiple nodes the main part of the application is executed by the CPUs and the intensive computing parts are run in. I just swap out my boot drive using a removable drive bay. Interactive jobs should use that same gres flag with the usual srun syntax for an interactive job.
Python gpu_monitoringpy sshpass -p my_password scp -o StrictHostKeyCheckingno gpu_utilization_100png. There are many reasons I think you are not root user the sacct display just the users job login or you must add the option -a or you have problem with your configuration file slurmconf or the log file of slurm it is necessary to check. Do nvidia-smi --query-gpuutilizationgpuutilizationmemorymemorytotalmemoryfreememoryused --formatcsv gpu_utilizationlog.
Those systems without such an interconnect are intended for either serial or parallel applications that can run within one node using either shared-memory or MPI within that node. Set each of these node-groups in the cluster. Nvidia Driver 41681 in TCC cluster and Cuda 10.
Cpu-linux-client Use m52xlarge general purpose instances with minimum size 1 and maximum size 4. Thus each GPU can provide peak performance of 3000 Gigaflops Billions of floating point operations per second. Given the heterogenity in the GPUs available you may want to request use of a specific GPU type.
The emphasis is to build a rsearch prototype GPU cluster using all open source Software and with minimal hardware. We can install it as follows. 2 Titan Vs and RTX 2070 Display Windows 10.
I9-7920X 128 GB DDR4 GPUs. Host nodes GPUs and interconnects. Sanity check results Checkout requested GPU devices from that file Initialize CUDA wrapper shared memory segment with unique key for user allows user to ssh to node outside of job environment and have same gpu devices visible Post-Job Use quick memtest run to verify healthy GPU state.
To get your MPI program run on the GPU machines you have to explicitly specify their hostnames otherwise your program will get started on the regular MPI backends which does not have any GPUs. A typical GPU cluster node has few 2-4 GPUs But a typical GPU cluster application is designed to utilize only one GPU per node Giving access to the entire cluster node is wasteful if the user only needs one GPU Solution. To do so you can add the.
Here is the relevant Conky script for Intel iGPU and nVidia GPU. If another user is using the GPU your job will be queued until the current job finishes. Use nvidia-healthmon to do GPU health checks on each job Use a cluster monitoring system to watch GPU behavior Stress test the cluster.
Processes are launched by logging into each node and starting each process manually. Please note that the CUDA. On a servernode GPUs are selected with export CUDA_VISIBLE_DEVICES see here and a conda environment should be active with required libs for your code.
I want to use an if statement inside my bash script to simply check if job123 is already running or in the queue. Less searches for the string VGA and it shows you the first matches it finds. Learn to build and operate basic GPU computing resources that provide end users with the latest CUDA features.
Provides per-process accounting of GPU usage using Linux PID Accessible via NVML or nvidia-smi in. Allow user to specify how many GPUs his application needs and fence the remaining GPUs for other users IOH. From that point you can scroll or page forward to see how many graphics cards lspci found.
ArwenDesktop srun --pty --partitiongpu --gresgpu1 binbash. Since the expectation is for the GPUs to carry out a substantial portion of the calculations host memory PCIe bus and network interconnect performance characteristics need to be matched with the GPU performance to maintain a well-balanced. Nvidia Driver 41072 not sure if need to cluster on Linux and Cuda 10.
General-purpose Clusters provide users with direct access to all nodes on the same network. Glmark2 is an OpenGL 20 and ES 20 benchmark command-line utility. Glmark2 Stress-testing GPU performance on Linux.
Monitoring Gpus In Kubernetes With Dcgm Nvidia Technical Blog

Perform Gpu Cpu And I O Stress Testing On Linux

How I Built A Gpu Deep Learning Cluster With Ray And Why I Would Do It Again By Alexander Mandt Medium
No comments for "Check Which User Is Using Each Gpu on Linux Cluster"
Post a Comment